Zaznaczam jednocześnie, że spędziłem sporo czasu na poznanie obu tych środowisk, co wcale nie oznacza, że znam je na wylot. Jak by się więc coś nie zgadzało w opisywanych przypadkach, to proszę o sprostowanie w komentarzu.
Podpowiedzi w kodzie
W Idei mamy tak:

wciskam Alt + Enter i mam:

Czyli zaimportowało mi żądaną kolekcję (a dokładniej interfejs kolekcji), który może być parametryzowany. A więc dokładnie to co chciałem i to jest najczęściej oczekiwane przez 99% developerów.
W Eclipse, chcąc zrobić to samo, otrzymuję długaśną listę, która ma mi niby pomóc:

Na co mi java.awt.List? I to na pierwszej pozycji? Przecież ona nie działa z typami generycznymi, więc powinno być jasne, że to się nie będzie kompilować. A skorzystał ktoś z was kiedyś z którejś opcji od 5 w dół? Idea widząc ten sam kod, patrzy nie tylko na nazwę klasy, ale i na to czy występują ostre nawiasy. Przecież generyki mamy w Javie od połowy 2004 roku.
Zgadywanie typów
Tworząc kod z wykorzystaniem TDD, często najpierw wybieram nazwę dla zmiennej, wywołuję jakąś metodę na niej, a na koniec się zastanawiam, czy powinna to być zmienna lokalna czy pole w klasie i jaki de facto powinien być zadeklarowany typ. W Idei robi się to bardzo przyjemnie (Alt + Enter):

i po wybraniu pierwszej opcji:

Idea proponuje mi, co będzie pasowało, skoro na danym obiekcie chcę wywołać metodę put(). W tym przypadku chcę mieć mapę i takowa podpowiedź jest dostępna.
A w Eclipse:

i po wybraniu drugiej opcji muszę sam przeskoczyć do nowo utworzonej definicji. Miało by to sens, gdyby tworzona automatycznie definicja dała się skompilować. Przeskakuję:

ale brak tu jakiejś sensownej podpowiedzi:

ReformatSettings to klasa, w której wklejałem ten kod, a więc zero pomocy ze strony środowiska.
Tworzenie instancji nowych obiektów
W Idei mamy Ctrl + Space:

Analogicznie w Eclipse:

A tu bieda aż piszczy. Nawet jak spróbujemy podpowiedzieć Eclipse’owi co ma zrobić, to i tak mu nie wychodzi:

W powyższym przykładzie próbuję utworzyć instancję klasy implementującej interfejs Map. Wpisuję HM, wciskam Ctrl + Space spodziewając się podpowiedzi, aby utworzyć HashMap’ę. Co dostaję? Jakieś HMACParameterSpec – klasa której nigdy nigdzie nie użyłem, nie wiem do czego służy i (najgorsze) która nie implementuje interfejsu Map.
A jak sprawa wygląda w Idei:
Jako podpowiedź dostaję jedyną słuszną klasę jaka w tym kontekście pasuje do zadeklarowanego interfejsu.
Dopasowywanie podpowiedzi do kodu
Na ten przykład natrafiłem tworząc jeden z postów: Logowanie interakcji w Mockito i jak się trochę nad tym zastanowiłem, że takie kodowanie to czysta przyjemność.
Na początek Idea. Mamy taki oto stan i piszemy właśnie konfigurację mocka:

Tutaj akurat zwykłe Ctrl + Space jakoś szczególnie nie zachwyca (jak to się mówi dupy nie urywa). Ale zobaczmy co się dzieje gdy wciskamy Ctrl + Shift + Space (Smart type).

I tutaj już Idea widzi, co można dopasować. Jako że metoda createUser() jako argumenty przyjmuje login i password, to pierwszą preferowaną opcja jest tutaj wcześniej utworzona stała LOGIN. Co ciekawsze to nie ma na liście analogicznej stałej, ale o nazwie PASSWORD, a która teoretycznie na podstawie typu pasuje! Czyż nie jest to powalające? Mamy również poniżej kilka ciekawych metod, które zwracają String’a jako rezultat, który może nam tutaj ewentualnie podpasować i metodę any() z Mockito! Skąd Idea wie, że jeśli się zabawiamy z Mockami, to w tym miejscu możemy (i ma to sens) wywołać tą metodę?
Idźmy dalej. Zatwierdzamy pierwszą propozycję (LOGIN) Enterem i ponownie naciskamy Ctrl + Shift + Space:

I znów analogiczna podpowiedź. Wybieramy pierwszą, właściwą opcję i Enter. Dopisujemy jeszcze co ma się stać po wywołaniu tej metody, czyli:

I teraz tak:
Ctrl + Shift + Space
Ctrl + Shift + Space
Enter
Ctrl + Shift + Space
Enter
Ctrl + Shift + Enter
I mamy wszystko czego nam do szczęścia potrzeba, razem ze średnikiem na końcu linii.
A w Eclipse:

Jedynie nazwy i typy argumentów. Na dalszym miejscu jest trochę lepiej, przy okazji new:

Po naciśnięciu Ctrl + Space:

mamy jakąś konkretną podpowiedź. Później jest już trochę lepiej:

Ale nadal nie jest to co w Idei.
Dopasowywanie argumentów metod
Kolejna sprawa z podpowiadaniem. Często jako argument metody pasuje tylko jeden typ (np. Enum). W przypadku podpowiedzi Eclipse’a jest trochę ubogo:

Dostajemy tylko nazwy argumentów. Trochę lepiej sprawa ma się gdy zaczniemy pisać nazwę oczekiwanego Enuma:

Tylko na co mi te wszystkie klasy od drugiej w dół? Przecież one w ogóle tu nie pasują. Mój argument jest prostym typem wyliczeniowym, który sam zdefiniowałem, który po niczym nie dziedziczy i nikt po nim nie dziedziczy, bo się nie da. Jest to niepotrzebne zaciemnianie ekranu.
Analogicznie w Idei, przy Ctrl + Space mamy coś takiego:

czyli możemy tą wartość wyczarować z obiektów które mamy (args, export), lub z Enuma. Jeśli chcemy podać konkretną wartość, to lepiej w tym wypadku skorzystać z Ctrl + Shift + Space:

i tu już mamy to co na pewno do sygnatury metody będzie pasować w bardziej zwięzłej formie. A jeśli nie pamiętamy tego skrótu klawiszowego (lub nie pamiętamy dokładnego znaczenia), to zawsze można napisać pierwszą literę potrzebnego Enuma i skorzystać ze standardowego Ctrl + Space:

I wtedy pasujące konkretne wartości typu wyliczeniowego zostaną dopasowane do otoczenia.
Uzupełnianie metod zależnie od kontekstu
Często mi się zdarza, że muszę zmienić nazwę metody, gdy mam już porządnie przygotowaną listę argumentów. Oczywiście w Eclipse działa to tragicznie. Przykładowo mamy taką sytuację:

Argumenty metody są już dobrze dopasowane, ale z jakiś względów początkowo źle wybrałem nazwę asercji. Zaczynam pisać poprawną nazwę metody, potem Ctrl + Space:

i dostaję podpowiedź w postaci różnych wariantów oczekiwanej metody. Wybieram pierwszą podpowiedź z brzegu:

i muszę od nowa uzupełniać listę argumentów. Bezsens!
Jak to działa w Idei? Po naciśnięciu Ctrl + Space również dostaję listę pasujących metod:

Wybieram pierwszą:

i wszystko się od razu dopasowuje do kontekstu.
Skróty klawiszowe
Skróty klawiszowe, to trochę delikatna sprawa. Jednym pasują te z Idei, innym te z Eclipse’a. Najczęściej zależy to od tego, których się wcześniej nauczyliśmy i jak bardzo się do nich przyzwyczailiśmy. A przyzwyczajenia to zło. Uznajemy czasem, że skróty są narzucone z góry i są logicznie poukładane. Czy na pewno?
Ctrl + D w Eclipse to usunięcie linii (delete), a w Idei skopiowanie w dół (duplicate). Jest to dla mnie największa bolączka, gdy się przesiadam z jednego środowiska do drugiego, gdyż jest to pierwsza różnica, która mi doskwiera. Do usuwania linii w Idei służy Ctrl + Y, co swoje korzenie ma w edytorze Vim (Yank – yy – usuwa aktualną linię). Ponadto Alt + F7 (wyszukiwanie użyć) i Shift + F6 (zmiana nazwy) mają swoje korzenie z Total Comander'a.
Kolejna sprawa (moja ulubiona), to te genialne czteroklawiszowe skróty w Eclipse, na których można się dorobić trwałego kalectwa palców: Alt + Shift + X, T – wystartowanie testów, lub czegoś innego w zależnie od ostatniej naciśniętej litery. Tą czynność wykonujemy bardzo często w cyklu TDD, więc ten hotkey powinien być łatwiejszy. Jak się doinstaluje MoreUnit, to jest trochę lepiej, ale jak pokazuję ten skrót niektórym kolegom (zwłaszcza tym starszym, którzy etap nauki i rozwoju mają już dawno za sobą), to wymiękają w tym momencie, twierdząc, że taka gimnastyka to dla nich za dużo. Dodatkowo tą ostatnią literę trzeba wcisnąć nie za szybko i nie za późno.
Kolejny super skrót to np. Alt + Shift + Q, C – przeskoczenie do konsoli. Można również przeskoczyć do innych widoków... Tylko co z tego, skoro aby wrócić do edycji kodu należy kliknąć myszką, lub Ctrl + F7? Skrajna ułomność i niedopatrzenie.
W Idei mamy problem przeskakiwania pomiędzy widokami o wiele lepiej rozwiązany. Do tego używamy Alt + numer widoku. A numery widoku mamy zazwyczaj widoczne na ekranie:

Są to te numerki tuż przy nazwie widoku. Dodatkowo, jak chcemy wrócić już do okna edycji to wciskamy po prostu Esc. Czyż to nie jest intuicyjne? A jak nam to okienko przeszkadza, to można wcisnąć Shift + Esc i je zamknąć, równocześnie przeskakując do okna edycji kodu. Można też ponownie skorzystać z kombinacji przeskakującej do aktualnego widoku (Alt + numer), która przy drugim naciśnięciu zamyka dany widok.
I tu wychodzi kolejna wyższość Idei nad Eclipsem. W Eclipsie mamy koncepcję perspektyw: Java, JavaEE, Debug itd. Jak się pomiędzy nimi przełączamy, to pewne widoki (views) znikają a inne się pojawiają, a jeszcze inne są trochę zdeformowane i na innych pozycjach. W Idei odpowiedniki Eclipsowych widoków pojawiają się i znikają „na żądanie”. Oczywiście wszystko sterowane z klawiatury.
Wracając do skrótów klawiaturowych. W Eclipse brakuje sporo ważnych skrótów, aby były od razu po instalacji dostępne. I tak bardzo często korzystam w Idei ze skakania od razu do implementacji (Ctrl + Alt + B). W Eclipse trzeba sobie samemu taki skrót podlinkować, np. Alt + F3, aby nie wiele się różnił od typowego skakania do deklaracji. Niestety nie wielu developerów wie o tej możliwości.
Przypisywanie wartości do pól, zmiennych lokalnych, stałych
W Eclipse mamy tzw. Quick Assist (Ctrl + 2), czyli przypisywanie do pola / zmiennej lokalnej, które działa bardzo kiepsko. Przykładowo w Eclipse dla takiego kodu:

nic nie da się zrobić, gdy kursor jest na końcu linii. Zresztą jak się zaznaczy kod od słówka new do końca linii to i tak Eclipse nic z tym nie wymyśli. Alt + Shift + L (Extract Local Variable) też nic nie pomoże. Idea natomiast radzi sobie z tym wyśmienicie:
Ctrl + Alt + V (Value):

Ctrl + Alt + F (Field)

Tutaj dodatkowo Idea sprawdza, czy to samo wyrażenie nie występuje jeszcze gdzieś w kodzie i sugeruje jego zastąpienie. Oczywiście z pomocą Alt + A można to zrobić bez konieczności użycia myszki.
Ctrl + Alt + C (Constans)

Tutaj dodatkowo Idea zapisuje stałą wielkimi literami, jak to się powszechnie w Javie przyjęło. Oczywiście wszystkie te refaktoringi można cofnąć za pomocą Esc lub Ctrl + Z. A jak w Eclipse wyeksportować do stałej? Mamy kolejnego łamańca: Alt + Shift + T, A, które i tak w przykładowym kontekście nie zadziała i do którego nie ma przypisanego standardowego skrótu.
Eclipse również sobie nie radzi jak ma trochę bardziej skomplikowane wyrażenie, którego wynik chcemy zapamiętać w zmiennej lokalnej. Przykładowo:

Nie działa ani Ctrl + 1, Ctrl + 2, ani Alt + Shift + L. Bieda! A w Idei Ctrl + Alt + V zachowuje się zgodnie z oczekiwaniem:

Idea pozwala nam zadeklarować pole jako final, zmienić przy tej okazji typ zmiennej, jak i sam dorzuca średnik na końcu.
Zaznaczanie tekstu
W Idei jest jeszcze cos takiego jak Ctrl + W (Incremental expression selection). W Eclipse jest niby coś analogicznego: Alt + Shift + Up, ale nie działa to tak fajnie jak w Idei.
Przesuwanie kodu w pionie
Kolejnym skrótem, którego mi bardzo brakuje w Eclipse jest inteligentne przesuwanie kodu Ctrl + Shift Up/Down (Move Statement Up). W Eclipse brak ekwiwalentnego skrótu, a działa on tak:
Przed:

Po:

Czyli po naciśnięciu Ctrl + Shift + Up cała metoda setName() została przeniesiona powyżej getName(), czyli tam gdzie ma ona sens. Jest to bardzo przydatna funkcjonalność podczas refaktoringu.
Komentowanie
Jeszcze irytująca mnie rzecz, to działanie Ctrl + / w Eclipse. Skrót ten wstawia komentarz w aktualnie zaznaczonych liniach, ale działa tylko w Javie. W przypadku plików XML, HTML i innych należy używać kolejnego, ale działającego wszędzie łamańca: Ctrl + Shift + C, zamiast prostego Ctrl + /. W Idei ten ostatni skrót działa wszędzie i wstawia komentarz zależnie od kontekstu w jakim się znajdujemy.
Refactoring
W Idei gdy zmieniamy nazwę pola w klasie (Shift + F6), które to posiada gettery i settery, to dostajemy zapytanie, czy te metody dostępowe również przeorać:

Dodatkowo Idea sugeruje, aby dopasować nazwę parametru w konstruktorze do nowej nazwy pola:

wciskamy spację, lub Alt + A aby wybrać wszystkie sugestie i Ctrl + Enter aby zamknąć okno. Następnie Idea jeszcze sugeruję nazwę pola, która jest użyta jako tekst w metodzie toString():

Oczywiście akceptujemy to za pomocą Alt + D i gotowe! Wszystko co chcieliśmy zostało dopasowane.
A w Eclipse? Eclipse zmienia tylko nazwę pola. Musimy sami pamiętać o getterach / setterach, konstruktorach i tekstach w toString(). Czyli mamy jakieś plus 4 więcej kroków do wykonania!
W Idei również działa całkiem dobrze (albo właściwie nie wiele gorzej) refaktoring, gdy go wykonujemy, gdy nasz kod się nie kompiluje. Dla Eclipse’a jest to najczęściej nie do wykonania.
Usability
Standardowo w Eclipse jest sporo ukrytych funkcjonalności. Czyli jeśli nie przeczytasz setki tutoriali, lub jeśli nie przeklikasz każdej opcji z okna Preferences, to będziesz mógł sobie tylko żyły wypruwać. I tak podczas Legacy Code Retreat, miałem spory problem z głupim wklejeniem tekstu wielolinijkowego do edytora tak, aby był traktowany jako String. Praktyczny przykład poniżej:

W Eclipse funkcjonuje to tak:

Czyli istna tragedia. Razem z osobą, z którą aktualnie byłem sparowany, straciliśmy z 10 minut, na doprowadzenie tego do stanu używalności, za pomocą metody find & replace. W Idei jest to out of the box:

Później jeszcze poszukałem chwilkę w necie i znalazłem rozwiązanie na to:
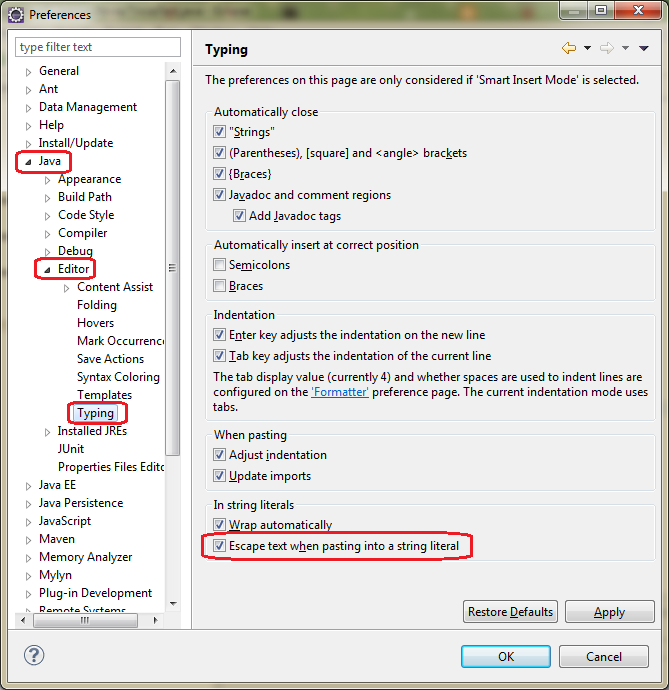
Źródło: http://stackoverflow.com/questions/2159678/paste-a-multi-line-java-string-in-eclipse
Inne, ogólne
Kolejny wielki błąd w designie Eclipsa to brak ciągłej synchronizacji pomiędzy tym co jest w edytorze a stanem na dysku twardym. Wystarczy czasem zrobić builda z zewnątrz lub jakiegoś update’a z repozytorium i podczas próby otwarcia pliku otrzymujemy coś podobnego do tego widoku:

Jeszcze jestem w stanie zrozumieć, że Eclipse nie odświeża sobie wszystkich plików ze wszystkich otwartych projektów (choć w Idei to działa dobrze i szybko), ale w momencie próby otworzenia pliku mógłby sobie już sam automatycznie to odświeżyć, zamiast wypisywać out of sync.
Dodatkowo jakość pluginów Eclipsowych jest bardzo słaba. Są one rozwijane po za podstawowym środowiskiem, czyli czasem działają, czasem nie, a po jakimś czasie autorzy często zarzucają jego rozwój. Tak się np. stało z MouseFeed, który przez długi czas nie działał z Eclipsem 4.X. Na szczęście plugin został ostatnio reaktywowany: Eclipse Mousefeed Plugin Merged With Marketplace Plugin. W przypadku innych pluginów nie wszystko zawsze dobrze działa. W Idei natomiast rozwój pluginów jest wspierany przez samych twórców, którzy dostarczają odpowiednią ich jakość i ich niezawodność.
Kilka dni temu (tj. 26 czerwca 2013) opublikowano nową wersję Eclipse'a 4.3 Kepler. Jeszcze jej nie sprawdzałem, ale pewnie nie wiele się zmieniło. Zrobię to pewnie za jakiś czas, jak już pluginy dostosują.
To chyba by było na tyle, choć jak by się chciało, to by się jeszcze znalazło parę Eclipse’owych niedogodności, ale wtedy nigdy bym nie opublikował tego posta. Następnym razem jak ktoś się mnie zapyta, „a co takiego ma Idea, czego nie ma Eclipse?” to go po prostu odeślę do tego artykułu.
A ty które wybierasz?
